Data Categorization For Analytical Purpose
What is Data Categorization?
Data Categorization is a process that helps the user/analyst to achieve certain analytical objectives like understanding the data or performing a comparison or a reconciliation between 2 data sets.
The outcome of this process enables the user to gain more understanding of the underlying data in order to be able to draw certain conclusions and highlight important findings directly related to the purpose of the analysis.
The outcome of this process enables the user to gain more understanding of the underlying data in order to be able to draw certain conclusions and highlight important findings directly related to the purpose of the analysis.
Why it is important?
Because without it the user will face lots of challenges in forming a complete understanding about the data and the messages that need to be concluded and won't be able to lay down these messages in a concise quantifiable method that will help in reaching the objectives of the analysis.
When Data Categorization becomes the Solution?
Excel users are often faced with cases where they need to work with a large data set that includes hundreds or thousands or even hundreds of thousands of rows. In many of these cases, the user would want to understand the data and make some related conclusions that will help with the analysis.
The solution is usually in producing a summary that explains the state of this data in certain defined groups that represent the important messages that should be highlighted in a quantified manner, in either volume and/or amounts depending on the type of analysis/reconciliation in focus.
The solution is usually in producing a summary that explains the state of this data in certain defined groups that represent the important messages that should be highlighted in a quantified manner, in either volume and/or amounts depending on the type of analysis/reconciliation in focus.
How it is done?
|
1. Determine the main objectives of the analysis
The user should ask himself/herself a series of questions to be able to determine the objectives of the analysis: • What is the main purpose of the analysis? • What is the most important information that needs to be concluded? • What is the success criteria for this analysis, meaning what is the definition of "Done" for this analysis? 2. Study the data Before starting any analysis the user need to have a very good understanding of the data in order to be able to determine the next steps. Also, lots of data quality checks on various dimensions need to be conducted to learn more about the state of the data including completeness, accuracy and reliability: • Do all columns have proper labels? • Are columns labels descriptive enough to help the user understand their purpose and the type of data in each of them? • If the columns labels are in codes, is there a data dictionary that includes the description of these columns? • What are the main key columns in the data? • Is there any NULLs or Blanks in any columns especially the key columns? • What is the number of rows/records in this data? This will help in estimating the impact on performance if formulas or any other kind of processing needs to happen later 3. Define the Data Categories Once you have a good understanding of the purpose of the analysis and what needs to be accomplished with it, and also has a very good knowledge about the health of the data and its main key columns, the next step is to come up with the data categories that will represent the summary of findings of the analysis. The user will need to focus on the following tasks which can be done in an iterative manner until you cover all rows: • Find commonalities between rows in relation to the analysis’ objectives identified in Step 1 • Decide whether this common pattern in certain rows qualifies as a good Data Category candidate to serve the objectives of the analysis • If the Data Category qualifies then it’s time to think how you will map the underlying rows to this Data Category • Insert a Data CATEGORY column in the data set in which this Data Category value will be assigned. That same CATEGORY column will also include all other identified Data Categories • Come up with the rules that need to be applied in the newly inserted CATEGORY column in order to map all rows under this group to the defined Data Category. The rules can be as simple as assigning a Text to the cells of the CATEGORY column for all related rows or it can be by applying a formula that helps identify this Data Category • Once you are done filter out this Data Category from the CATEGORY column and repeat the same steps for any unidentified rows i.e. rows that still don’t have any assigned Data Category • You might need to have an “Other” Data Category at the end in cases where you couldn’t map certain rows to a particular Data Category Tips: Ideally, the number of defined Data Categories shouldn’t exceed 10 categories at the most so the findings summary is more focused and concise and can help draw the conclusions required as part of the analysis objectives 4. Aggregate the count/amount of all Data Categories Now that you have in the data a column that can explain all possible data groups and types, all what you need to do is to aggregate the count and/or amount related to all these groups so you can have a summary of findings that can be used to make the right conclusion. The best automated method in Excel for applying any type of aggregations is the Pivot Table and if you are familiar with it, in the matter of seconds you can have a nice summary of the count or related amount of each of the Data Categories in the CATEGORY column. 5. Use the outcome of this process to make conclusions and decisions Use the list of aggregated Data Categories to make reasonable conclusions by always relating back to the objectives of the analysis so you can at the end make the right decisions. |
|
Use Case scenario
|
Adam is a Senior Data Analyst working in the HR Department of a major Insurance company and he was provided with a list of the company employees' information in an excel worksheet and was asked to analyze the data and present and share some important findings about the data.
Adam decided to follow these steps in order to ensure that the outcome of this analysis will be useful and will benefit senior management in making the right decisions about related employees data processes and systems enhancements: 1. Adam asked for more information about the purpose of this analysis and found out that the main goal is to have a good understanding about the completeness and data quality of the employees' information in this data set. 2. Then Adam decided to examine the data and he found that it includes the following columns: Employee_ID First_Name Last_Name Address Date_Hired Position Dep_Code Salary Adam took notes of some important observations about the employees data including the followings: - The worksheet includes 45,732 rows excluding the row for the header - The Employee_ID column is the unique identifier of the employees and it's the main key to be used to identify an employee - Although column First_name doesn't have any NULLs or Blanks but it seems some employees have both first and last name populated in the First_Name column and for these employees the Last_Name column in Blank/Empty - The Position field in not always populated with values and in many of these rows the Salary is also Blank - The Salary column format is not always consistently in an amount/number format, for example "35k" instead of "$35,000" - The data includes more than one entry of the same employee by finding matching rows with same information except the Employee_ID which seems to be different - Adam also noticed that few department codes under the Dep_Code column don't exist in the reference department code list - There is lots of rows with good data and no data quality issues 3. Adam now has a good understanding about all the issues in the data and the Categories that he can create to help explain these issues. However, before even Adam had identified all these issues and reach the point where he has a full understanding of the issues, he inserted a column in the data (anywhere inside or adjacent to the data so it can be picked up by the Pivot Table) and he labeled it "CATEGORY" and every time he identified an issue he populated the CATEGORY column with the correspondent category type. Adam was mapping the employee rows to one of the identified Categories by either:
Once one Category is mapped to the relevant rows then Adman filters out these row using the newly inserted CATEGORY column and he continued looking at the rows that are still not assigned a category type. Note: Sometimes some adjustments might be required during the mapping process to the Categories or even after the first round of Categories identification is completed by either combining more than one Category into a new bigger Category or by splitting one Category into many smaller categories. Good judgment needs to be used to come up with the best level of Categorization that is most suited for the analysis. 4. Adam aggregated the CATEGORY column using a Pivot table and got the count of each Category Group as well as the percentage of each CATEGORY count from the overall data rows count and it was as follows: |
|
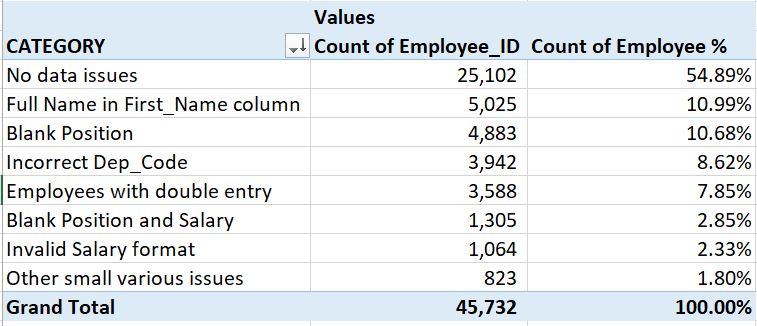
Note: In some cases a SUB CATEGORY column might be a good idea to have in order to show the findings using two levels of details. The CATEGORY column will show a higher level which can be broken down by the SUB CATEGORY column.